- Published
Top 10 Code Smells to Identify in Pull Requests with Code Examples
- Authors

- Name
- Sydney Cohen
- @chnsydney
As a developer, few things are more satisfying than reviewing pull requests and catching code smells. It's like finding hidden treasures in your codebase, except instead of gold coins, you get to refactor confusing code you wrote 6 months ago.
Fear not, dear developer, for in this article, we'll explore the top 10 code smells to keep an eye out for in pull requests. By offering examples and useful suggestions on how to address them, you'll develop the ability to efficiently navigate your codebase. This will enable you and your team to create code that is cleaner and more maintainable.
Top 10 Code Smells in Pull Requests
- Large or complex methods
- Long parameter lists
- Excessive comments
- Duplicate code
- Inconsistent naming conventions
- Incomplete error handling
- Too many if/else statements
- Poor use of inheritance
- Unnecessary dependencies
- Magic numbers or hard-coded values
A method that is too long or complex can be difficult to understand and maintain. It can also make the code more error-prone and difficult to test. Breaking the method into smaller, more focused methods can make it easier to understand and maintain.
A good way to avoid that is to implement a linter that forbids function that are more than x lines of codes.
Here is an example of a large and complex JavaScript method:
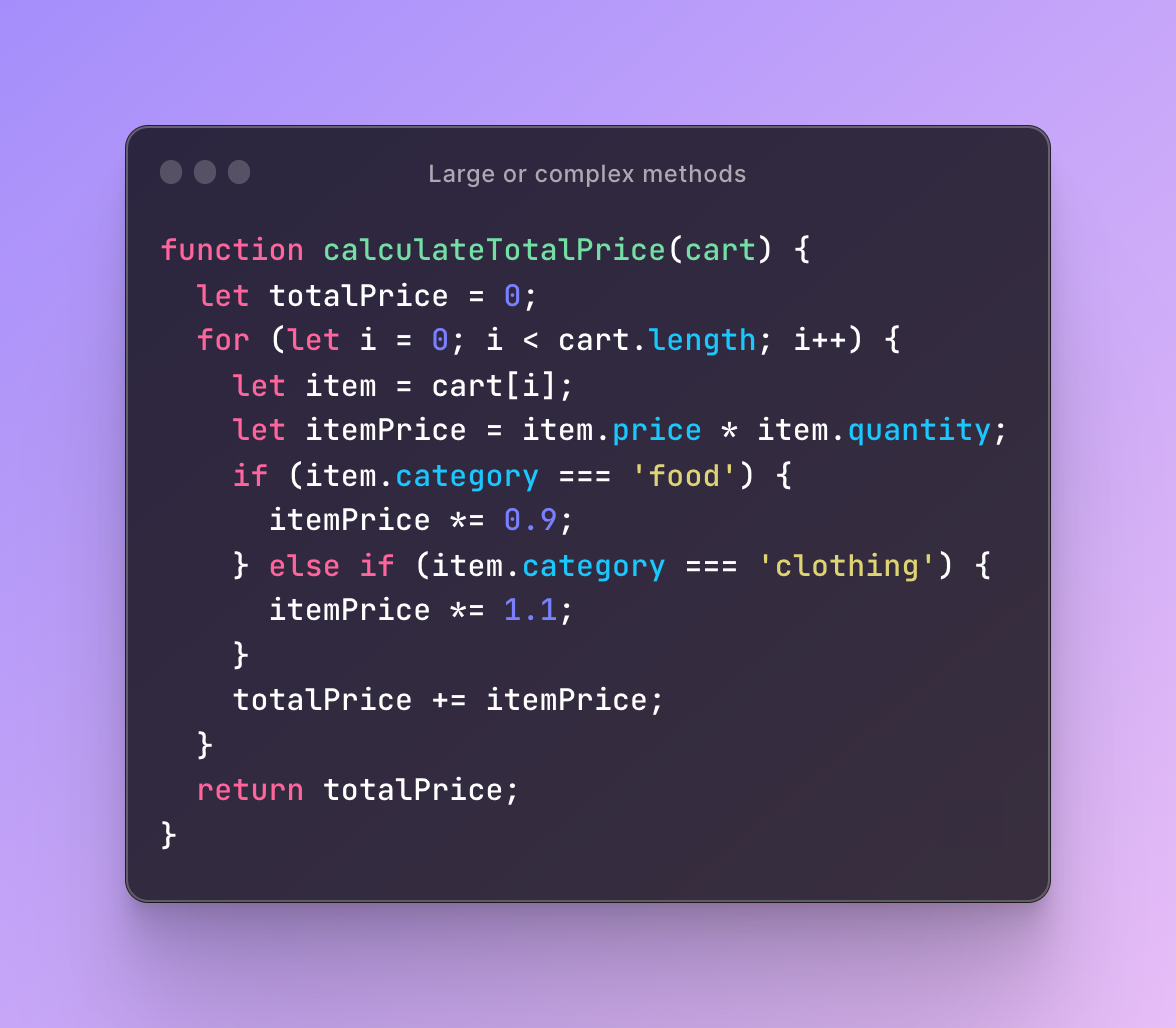
This code violates the Single Responsibility Principle (SRP) and is difficult to read and maintain. The calculateTotalPrice function is responsible for iterating through the cart array, determining the price of each item, and calculating the total price. This makes the function lengthy, hard to understand, and prone to errors.
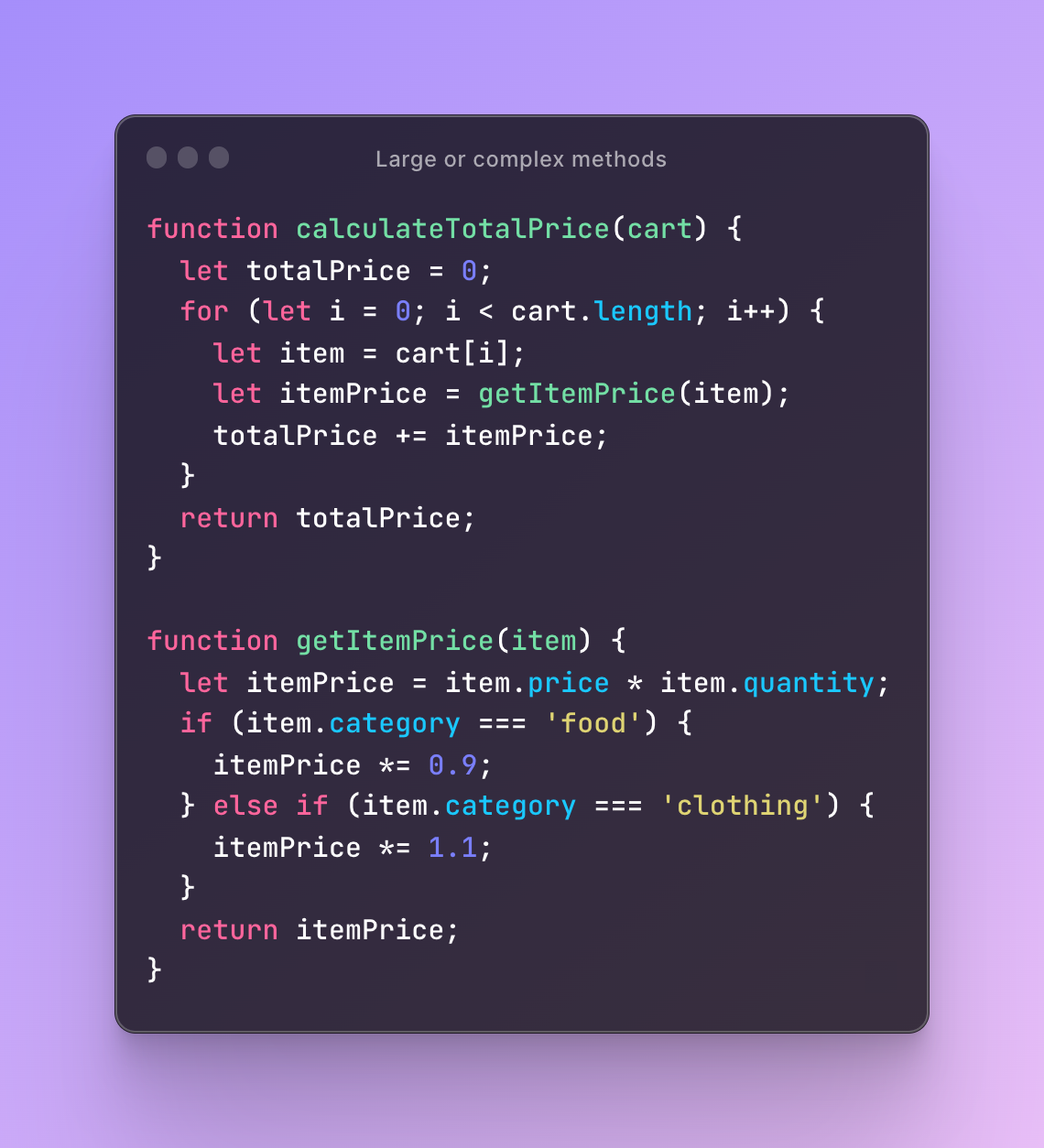
The solution to this code smell is to extract the item price calculation into a separate function getItemPrice(item) that takes an item object as an argument and returns the calculated price. This way, the calculateTotalPrice function is responsible only for iterating through the cart and adding up the item prices. The code becomes more modular, easier to read, and less error-prone.
Additionally, this solution allows for easier testing and reusability of the getItemPrice function. Now, other functions in the codebase can call getItemPrice with an item object to get the item price, without having to duplicate the price calculation logic.
Overall, this solution improves the code quality by promoting modularity, readability, and maintainability.
A method with too many parameters can be difficult to understand and use. It can also make the method more error-prone and difficult to test. Reducing the number of parameters or grouping related parameters into objects can make the method easier to use and maintain.
Here is an example of a function with a long parameter list in JavaScript:
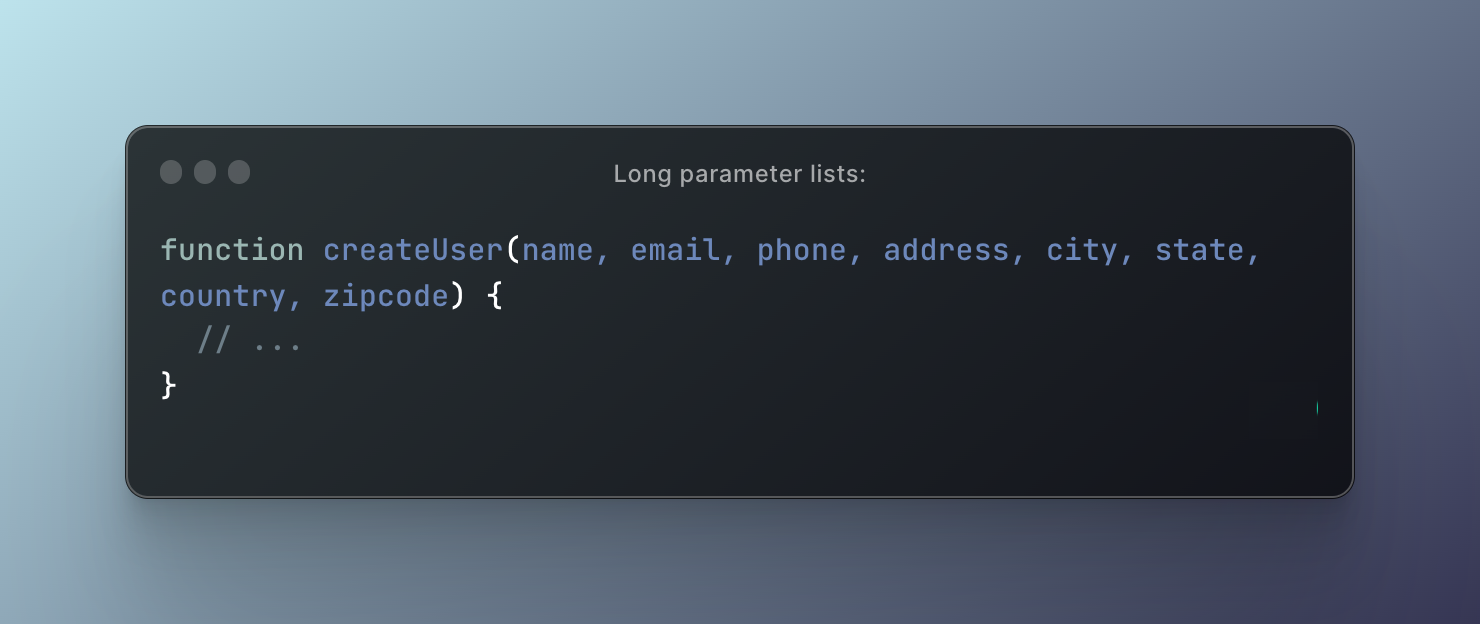
In this example, the createUser function has eight parameters, which can make it hard to use and understand.
One solution to this problem is to use an object or an array as a parameter instead of individual arguments. This approach is called the "parameter object" pattern. Here is an example of how this can be done:
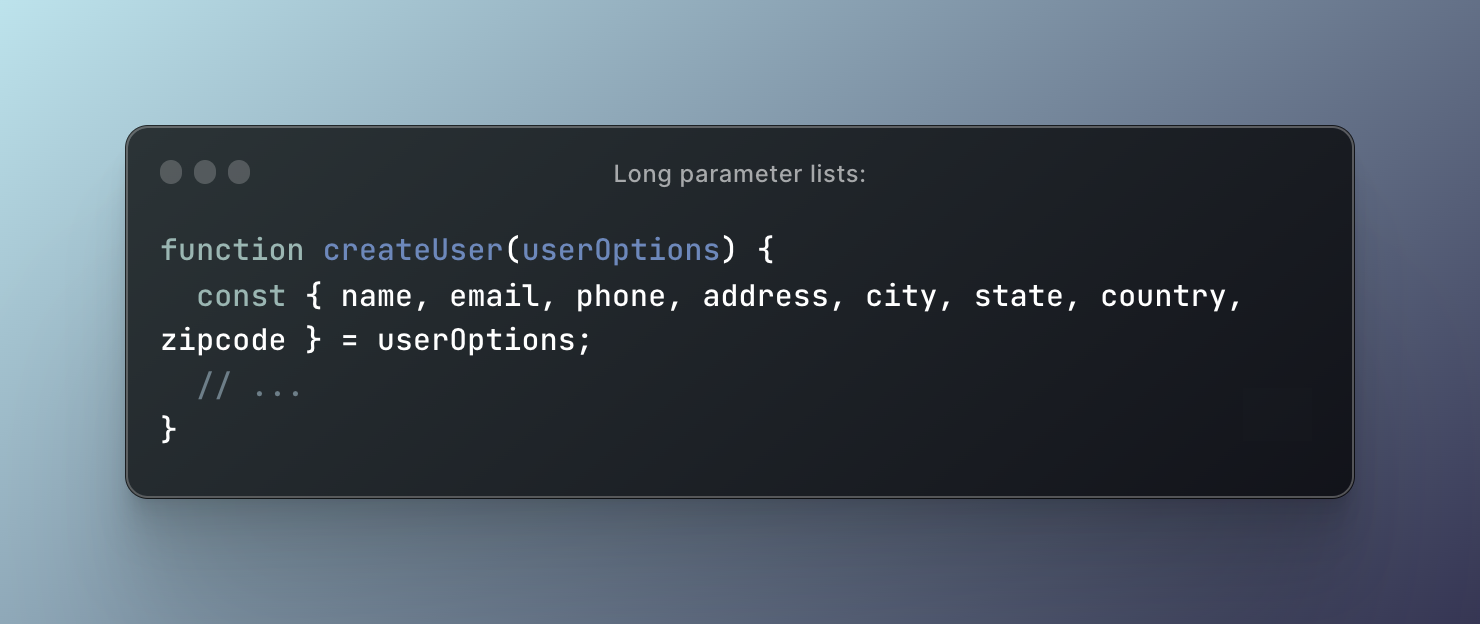
In this example, the createUser function now takes only one argument, which is an object that contains all the necessary parameters. The options object can have default values for some parameters, and the function can destructure the object to access its properties. This approach makes the function more readable, easier to use, and more maintainable.
While comments can be helpful in explaining code, too many comments can make the code difficult to read and maintain. It can also be a sign that the code is not self-explanatory and may need to be refactored.
Here is an example of excessive comments in JavaScript:
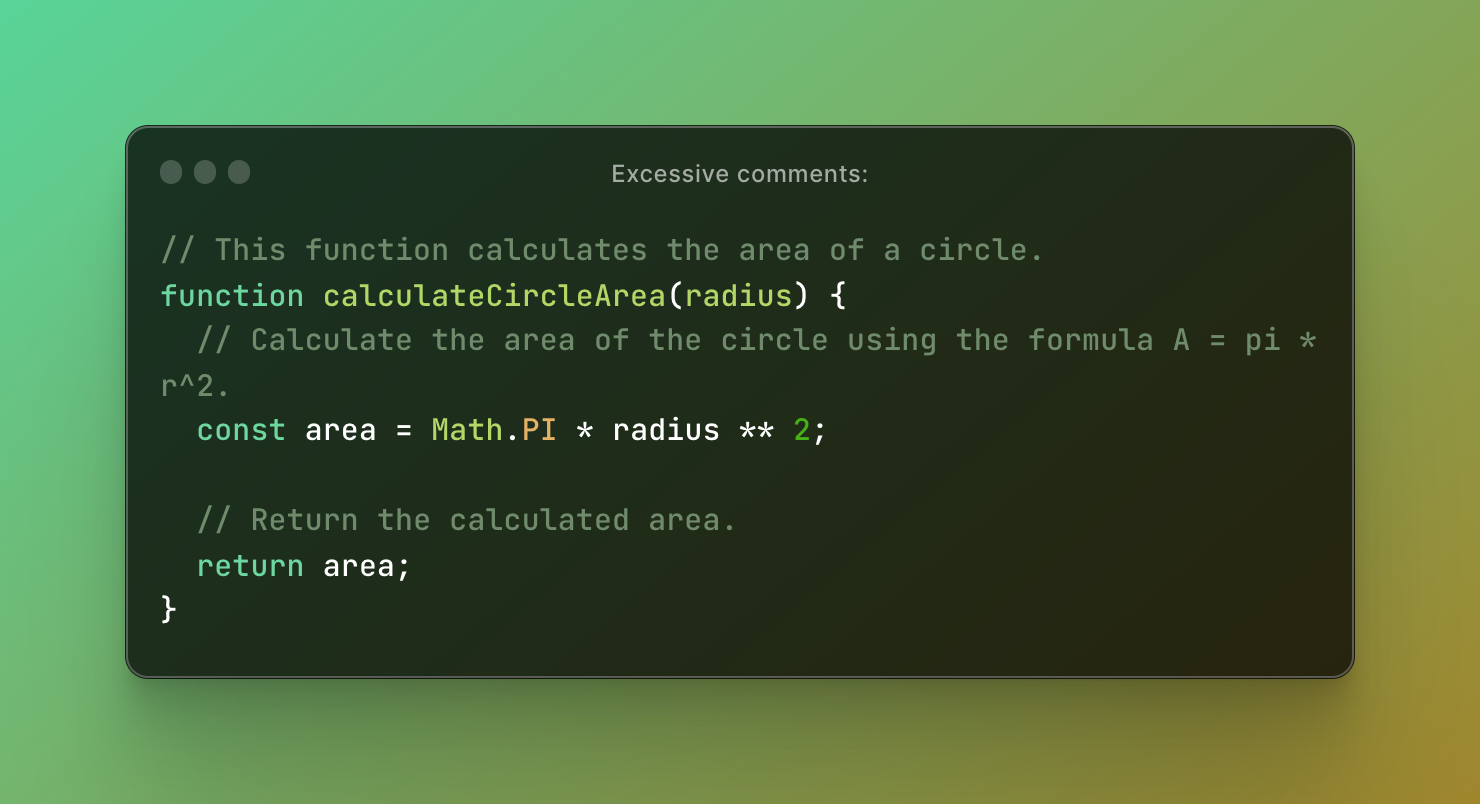
The problem with this code is that it contains an excessive comment. The comment is redundant and does not add any meaningful information that isn't already conveyed by the function name and the code itself. This makes the code harder to read and maintain, as the comment may need to be updated along with the code if any changes are made.
A better solution would be to remove the comment and rely on clear and descriptive function and variable names to convey the purpose of the code. Here's the revised code:
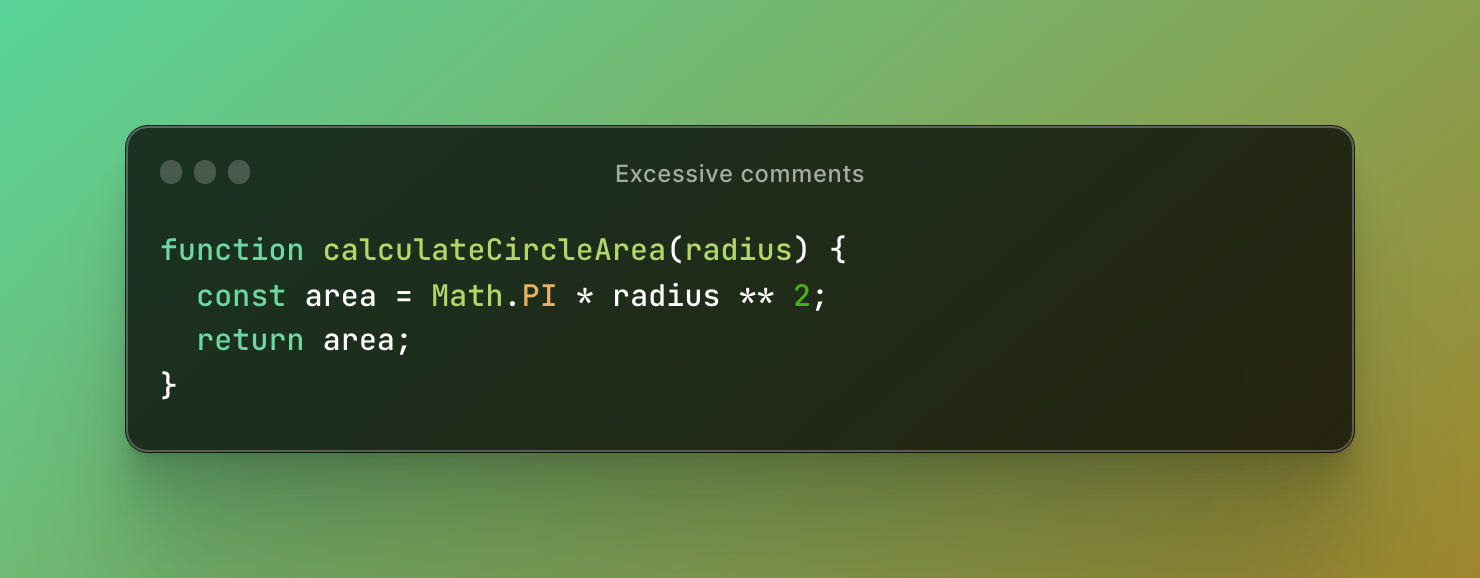
As you can see, the code is now self-explanatory and easy to understand without the need for an excessive comment.
Copying and pasting code can result in duplicate code that is difficult to maintain. It can also lead to inconsistencies in the codebase. Refactoring the duplicate code into reusable methods or functions can make the code easier to maintain and more consistent.
Lets take an example of duplicate code in JavaScript:
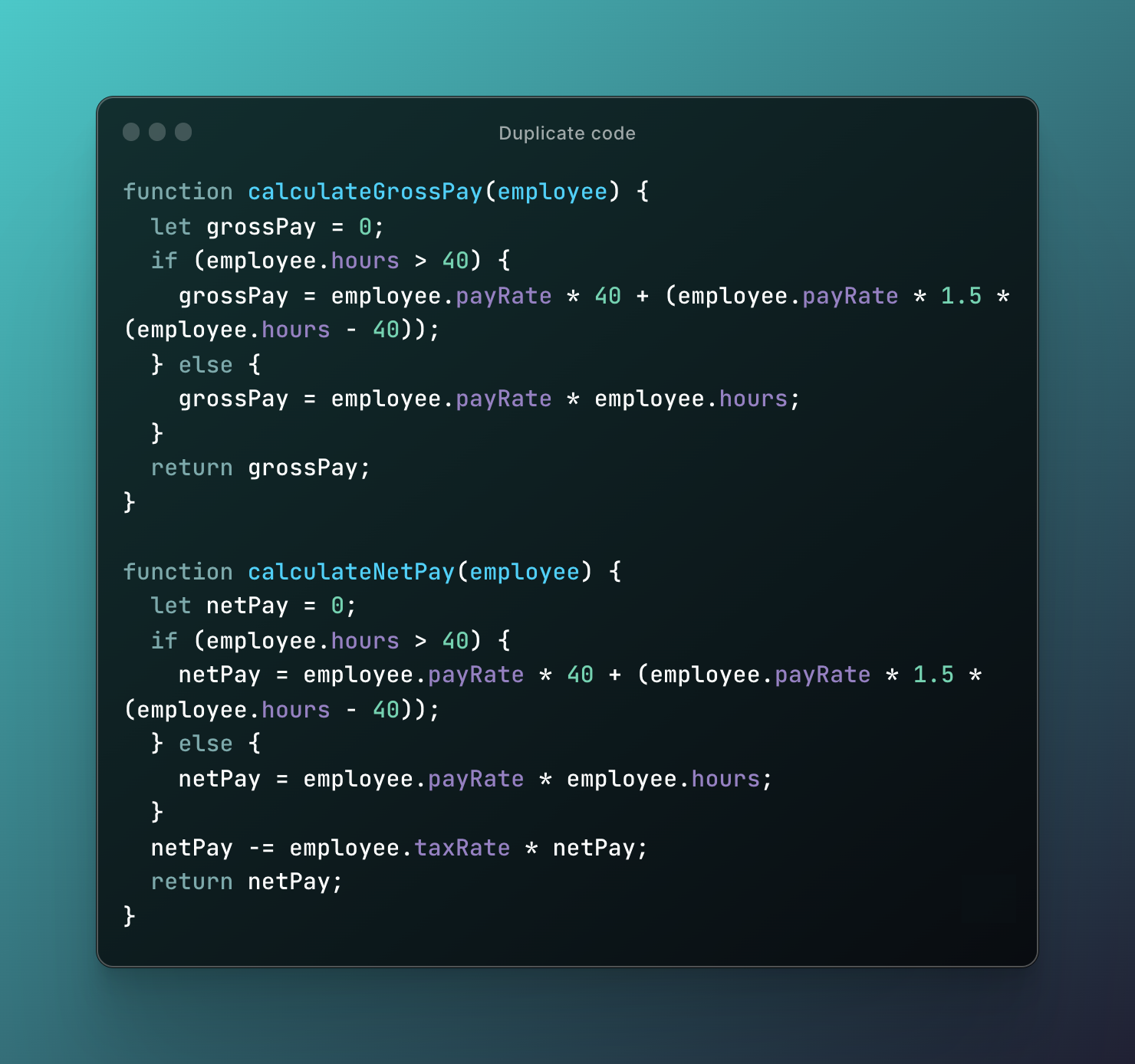
The problem with this code is that there is some duplicated code within the if statement and the else statement. Specifically, the calculation of the gross pay involves multiplying the number of hours worked by the pay rate, but with different coefficients depending on whether the hours worked are above or below 40. This same calculation is duplicated in both branches of the if statement, which can be a source of errors and make the code harder to maintain in the long run.
One possible solution to this problem is to extract the duplicated code into a separate function, which can be called from both branches of the if statement. Here's an example of how we could refactor the code using this approach:
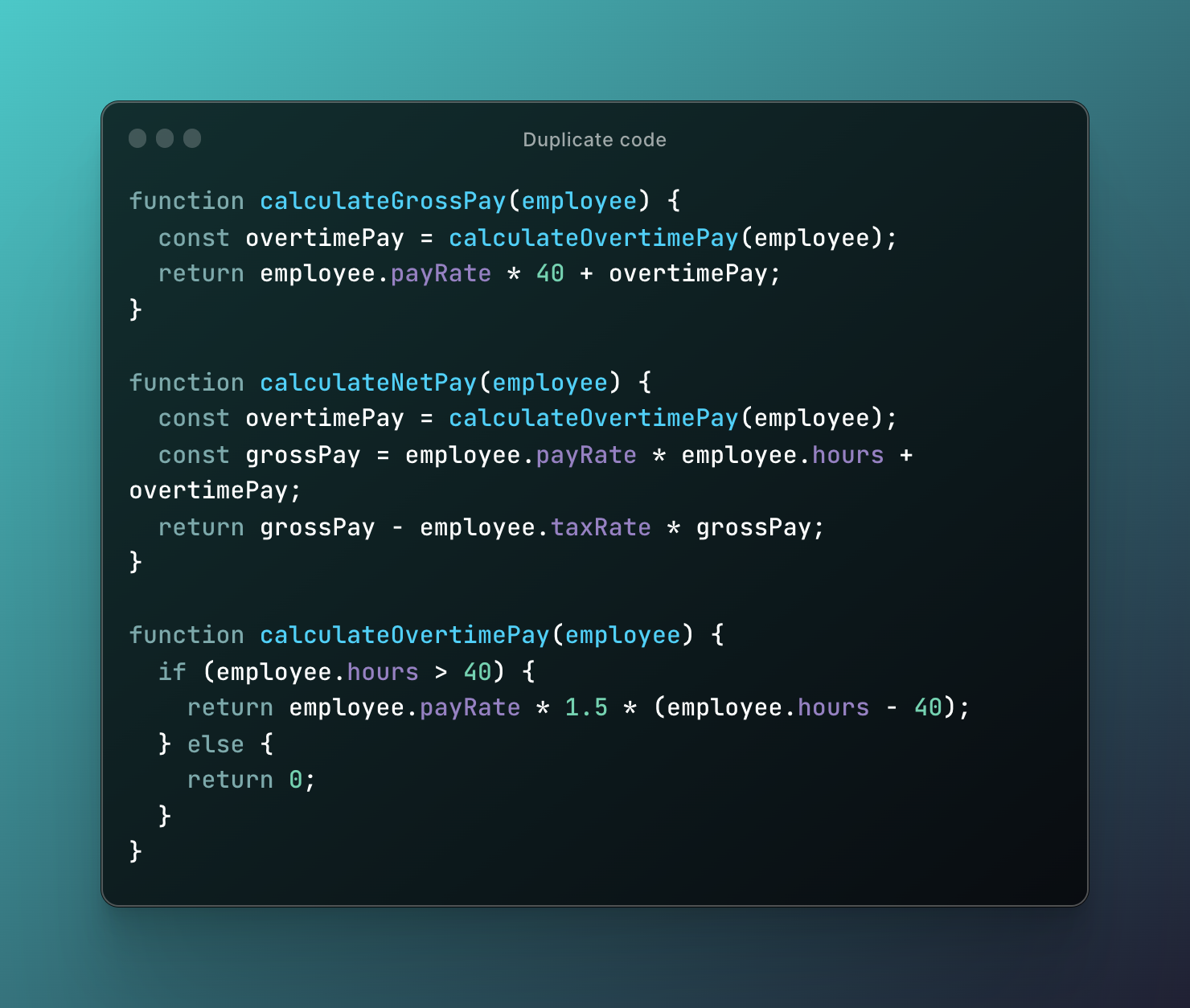
In this refactored code, we have extracted the calculation of the regular pay into a separate function called calculateRegularPay(), and the calculation of the overtime pay into a separate function called calculateOvertimePay(). The calculateGrossPay() function now calls these functions instead of duplicating the calculation code. This makes the code more modular and easier to maintain, as changes to the calculation of regular pay or overtime pay only need to be made in one place.
Inconsistent naming conventions can make the code difficult to read and understand. It can also lead to confusion and errors. Adopting a consistent naming convention can make the code easier to read and maintain.
Here is an example of inconsistent naming conventions in JavaScript:
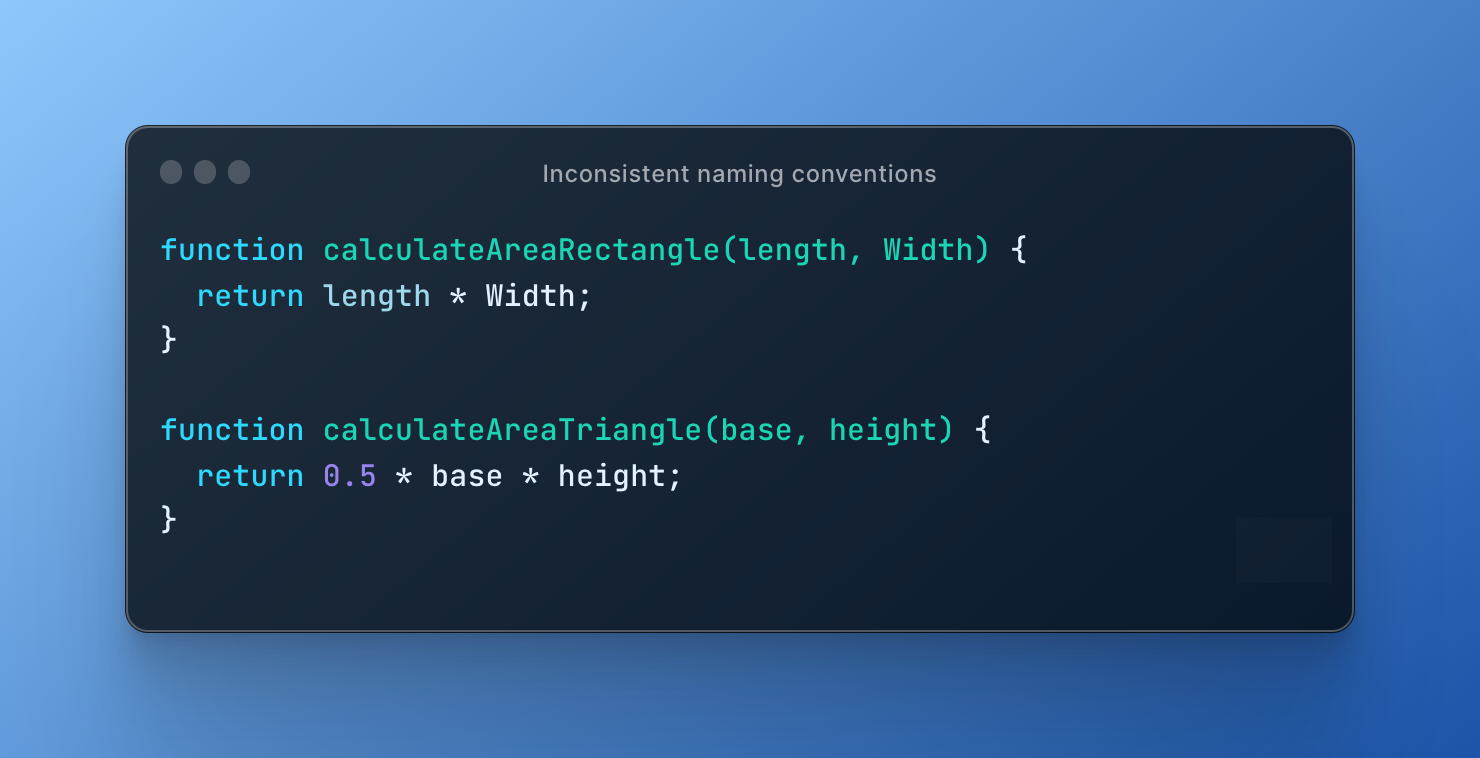
In this example, there are two functions for calculating the area of a rectangle and a triangle. However, there is an inconsistency in the naming conventions used for the parameters of these functions. The first function uses "length" and "Width" (with a capital "W"), while the second function uses "base" and "height" (all lowercase).
To address this issue, we can modify the code to use consistent naming conventions:
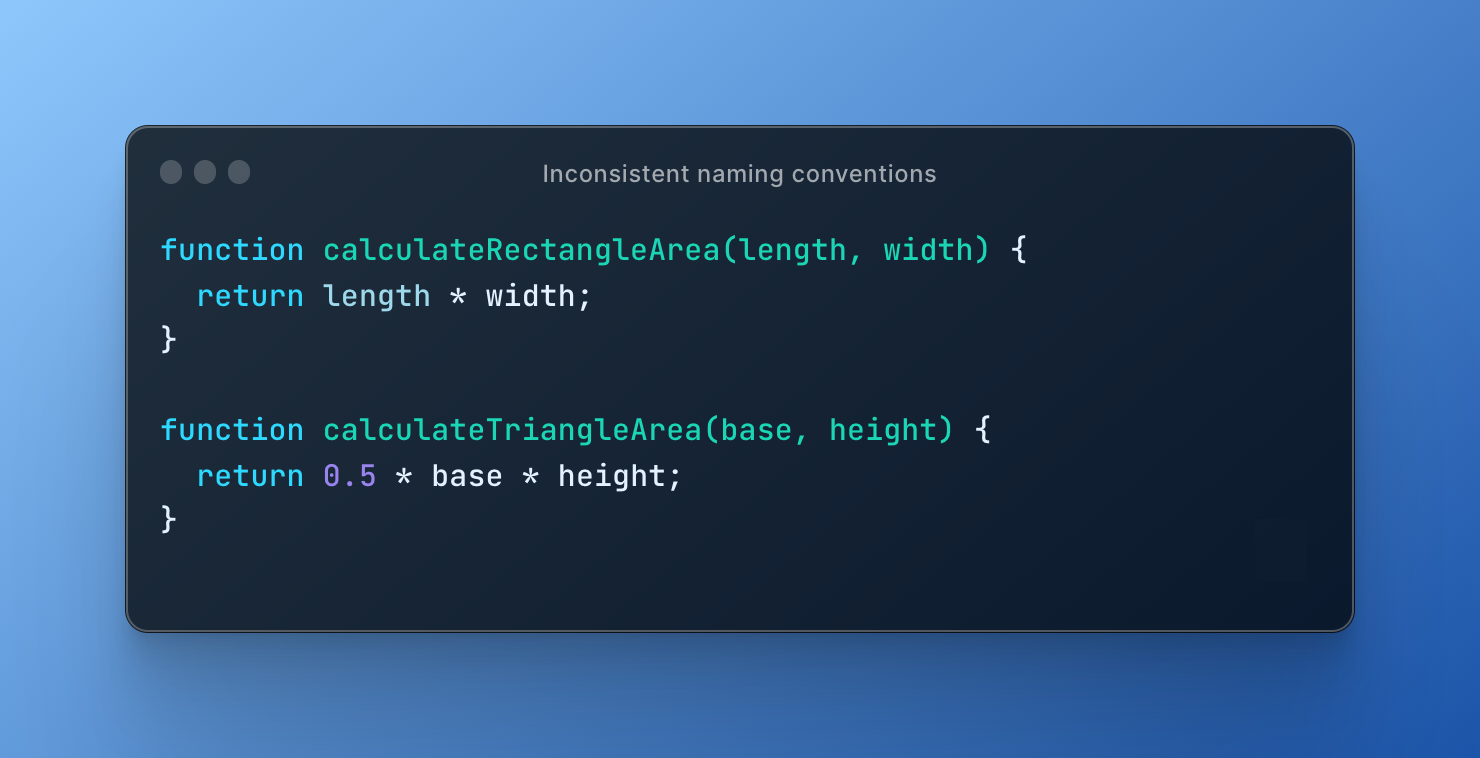
In this updated code, we have modified the function names to use consistent naming conventions for their respective shapes. Additionally, we have ensured that the parameter names within each function use the same case for each letter. This makes the code more readable and easier to understand, and can help prevent errors caused by confusion over parameter names.
Failing to handle errors properly can result in unpredictable behavior and errors. It can also make the code more difficult to test and maintain. Properly handling errors can make the code more reliable and easier to maintain.
Here is an example of incomplete error handling in a JavaScript function:
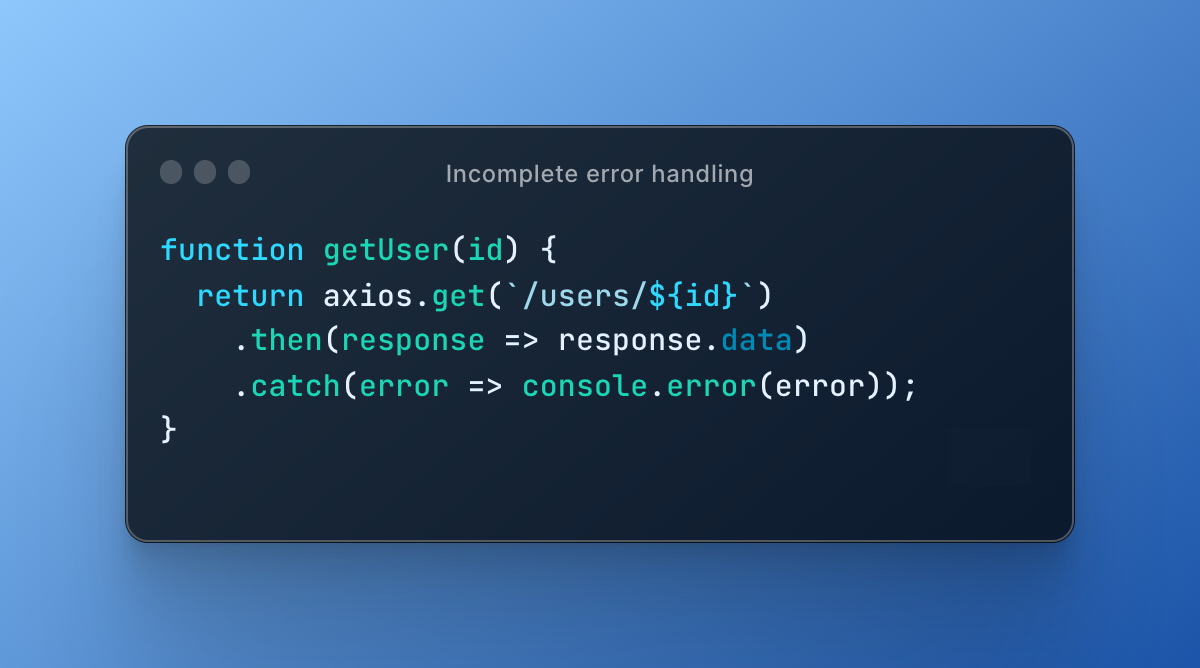
The problem with this code is that it does not handle the error properly. If there is an error while making the API call, the function simply logs the error to the console and returns nothing. This can be a problem for the calling code, which might expect some meaningful response.
Here's an example of how to improve the error handling:
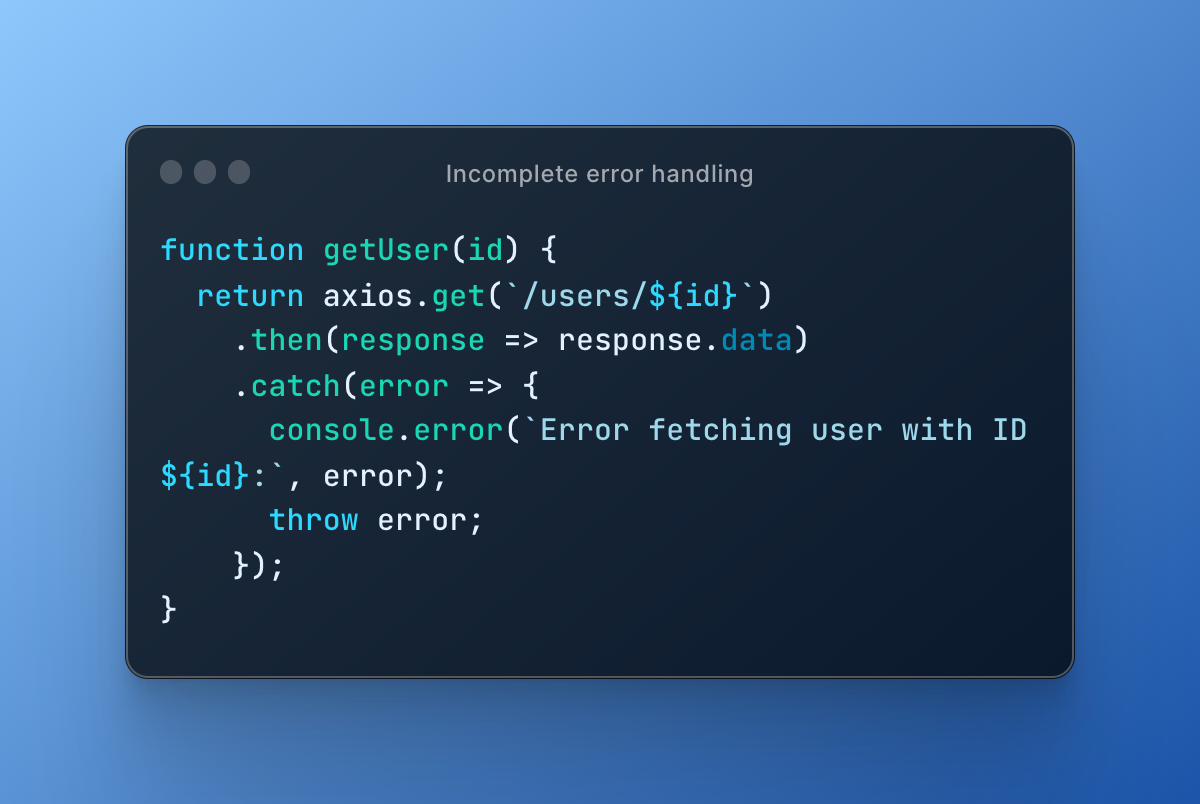
In this code, if there is an error while making the API call, the error is logged to the console with a meaningful message, and then it is thrown so that the calling code can handle it appropriately. This way, the code is more robust and can handle errors more gracefully.
If/else statements can make code difficult to read and maintain, especially when they are nested or numerous. Code that contains too many if/else statements can be a sign of poor design and could benefit from refactoring using techniques like polymorphism or strategy patterns.
Here is an example of too many if/else statements in JavaScript:
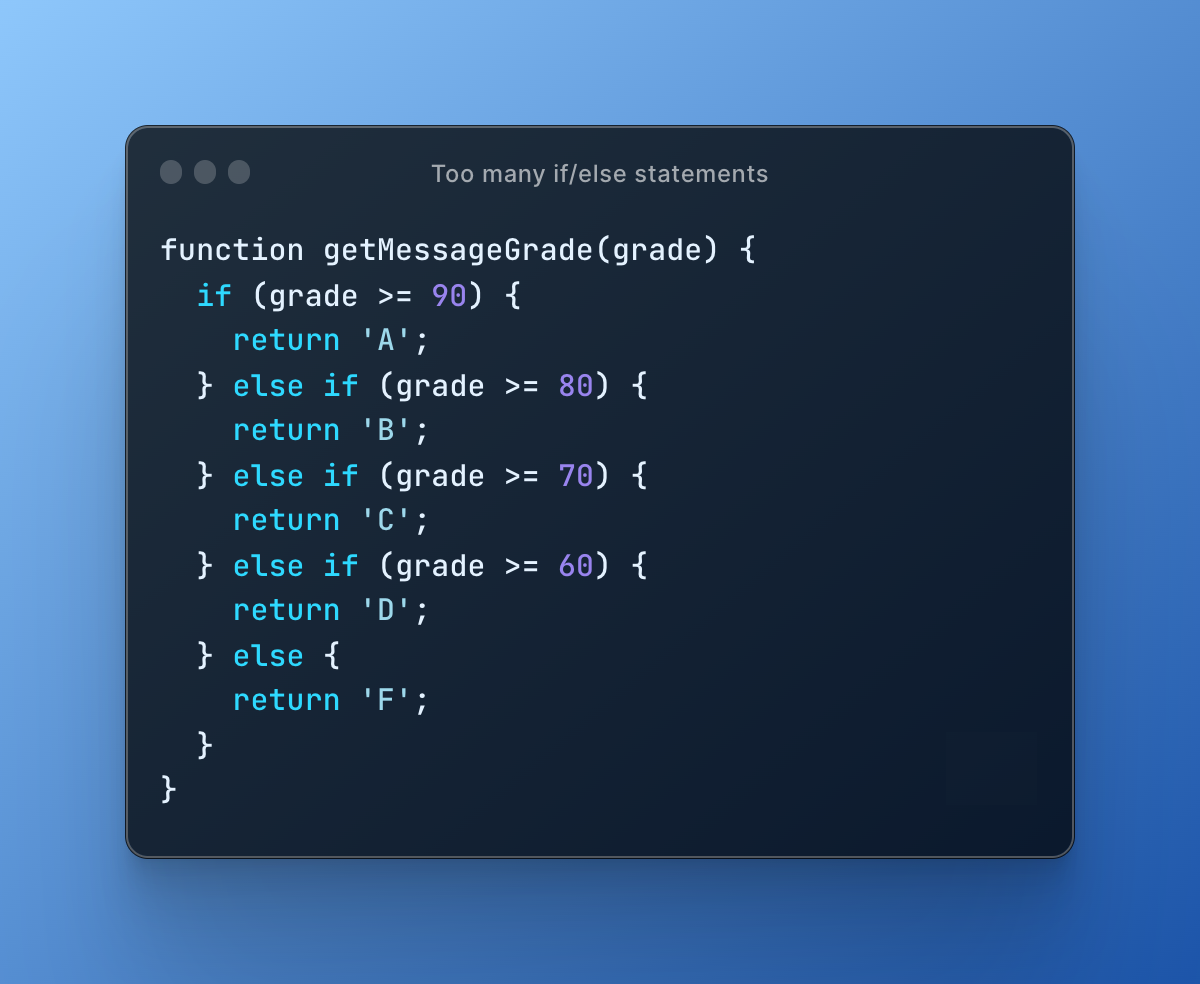
In this example the getMessageGrade function has multiple if/else statements to determine the letter grade based on the numerical grade provided.
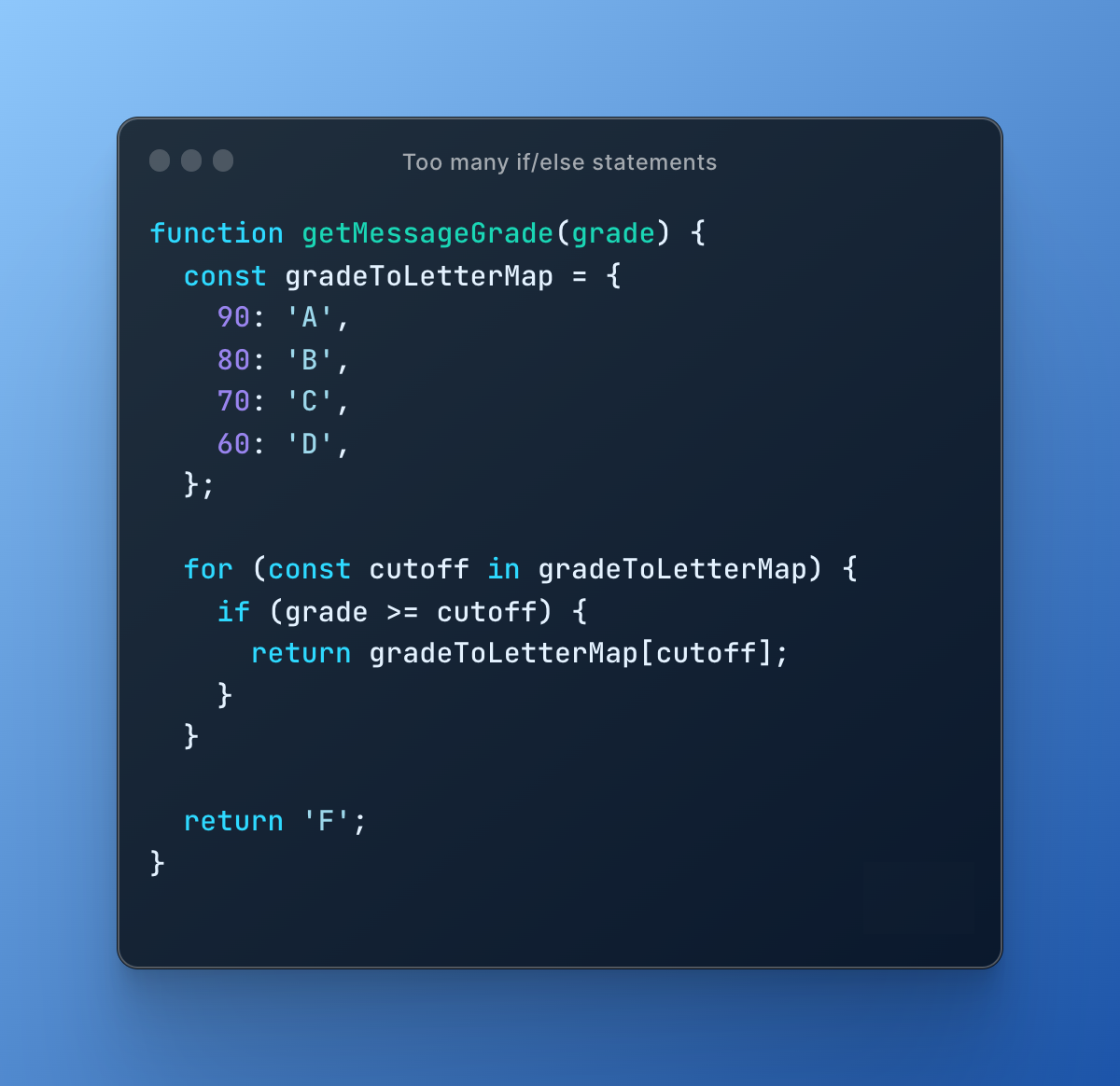
The solution to this code smell is to use a data structure to map the numerical grades to their corresponding letter grades. In the second example provided, instead of using multiple if/else statements, an object gradeToLetterMap is used to map numerical grades to their corresponding letter grades. A for...in loop is used to iterate over the object and return the corresponding letter grade for the numerical grade provided. If the numerical grade is lower than the lowest cutoff, it returns a default grade 'F'.
By using a data structure to map the numerical grades to letter grades, the code becomes more readable and maintainable. If there is a need to change the grading scale in the future, the changes can be made in one place, in the data structure, rather than having to update multiple if/else statements throughout the code.
Inheritance can be a powerful tool for creating reusable code, but poor use of inheritance can lead to code that is difficult to understand, maintain, and extend. Code that relies heavily on inheritance can become tightly coupled and inflexible, and can lead to issues like the fragile base class problem.
Here is an example of poor use of inheritance
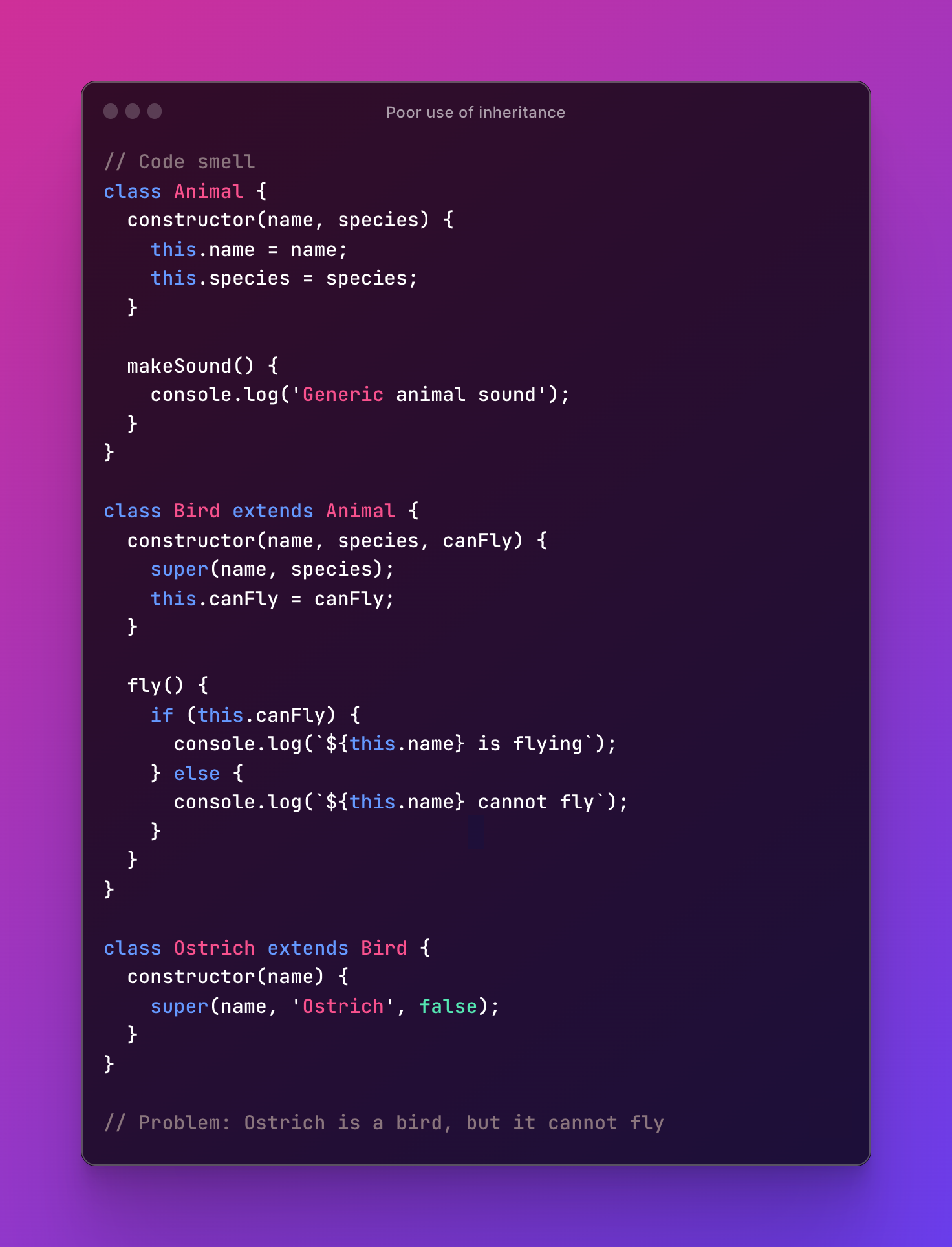
The problem with the initial code is that it violates the Liskov substitution principle, as it defines the Ostrich class as a subclass of Bird even though it cannot fly. This creates confusion and inconsistency in the code.
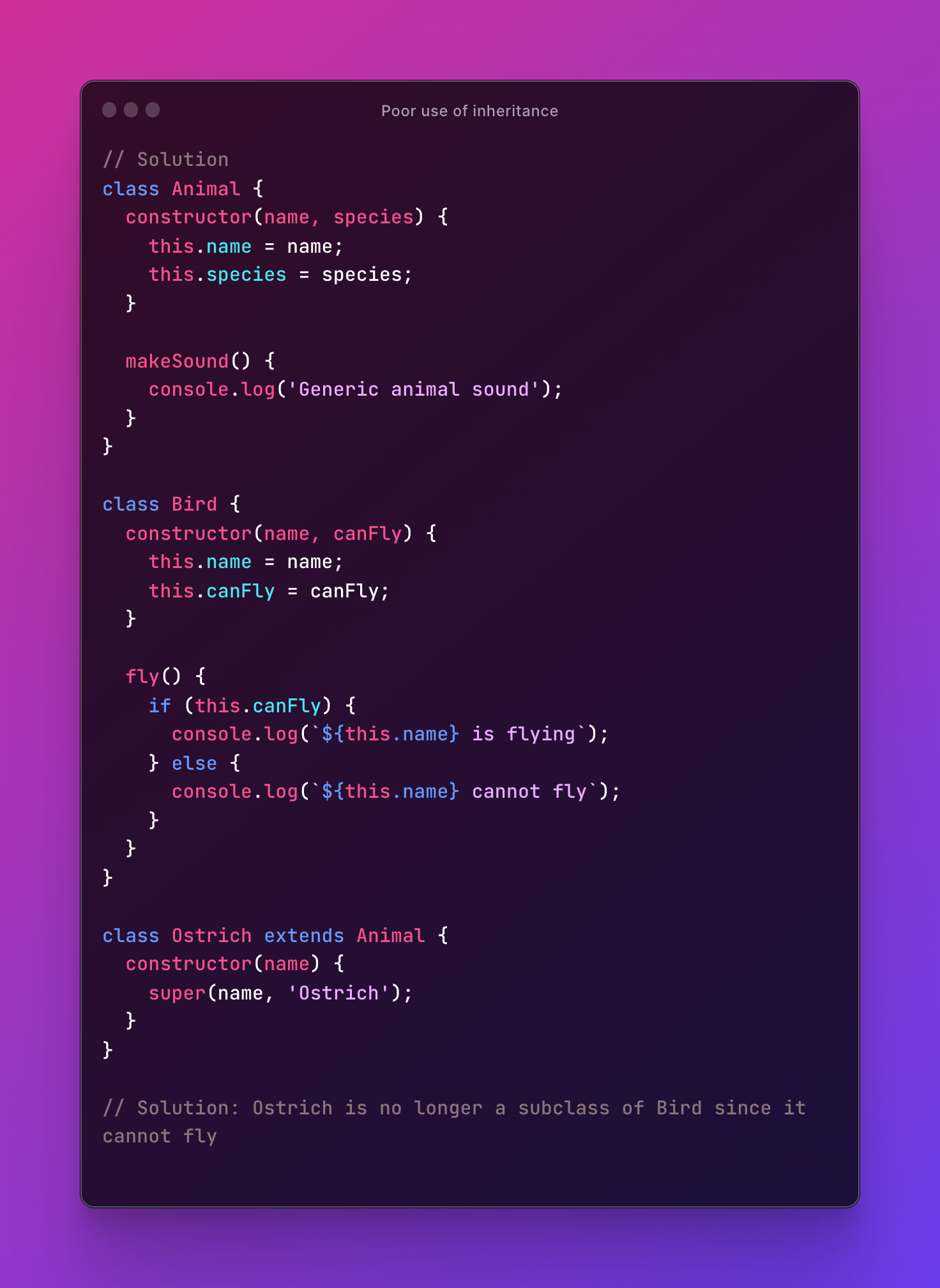
The solution is to remove the inheritance relationship between Ostrich and Bird and instead make both classes inherit from a common superclass, Animal. This way, Ostrich is still a type of bird, but it does not inherit any flying-related behavior from its parent class.
Unnecessary dependencies occur when code depends on external libraries, frameworks, or components that are not actually required. These dependencies can add unnecessary complexity to the code, increase the risk of conflicts or bugs, and make it more difficult to maintain and update the code.
here is an example of unnecessary dependencies:
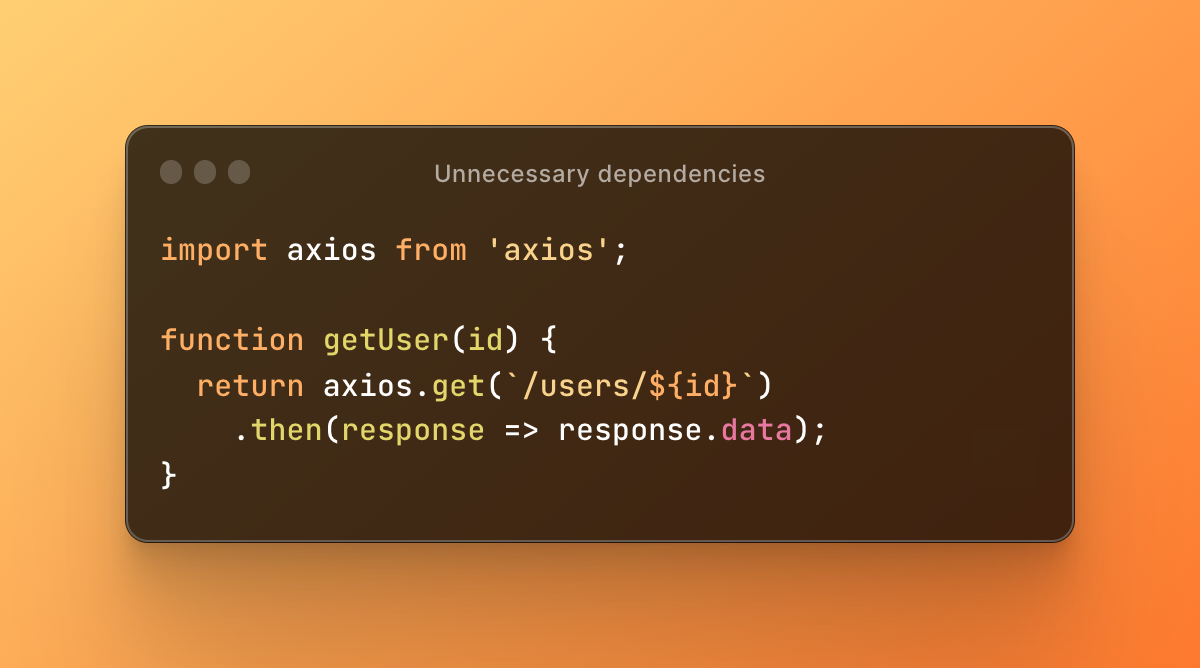
In the example given, the code is dependent on the Axios library to make a simple HTTP GET request. Axios is a powerful and feature-rich HTTP library that is overkill for this use case. A more lightweight alternative like the built-in fetch API can be used instead.
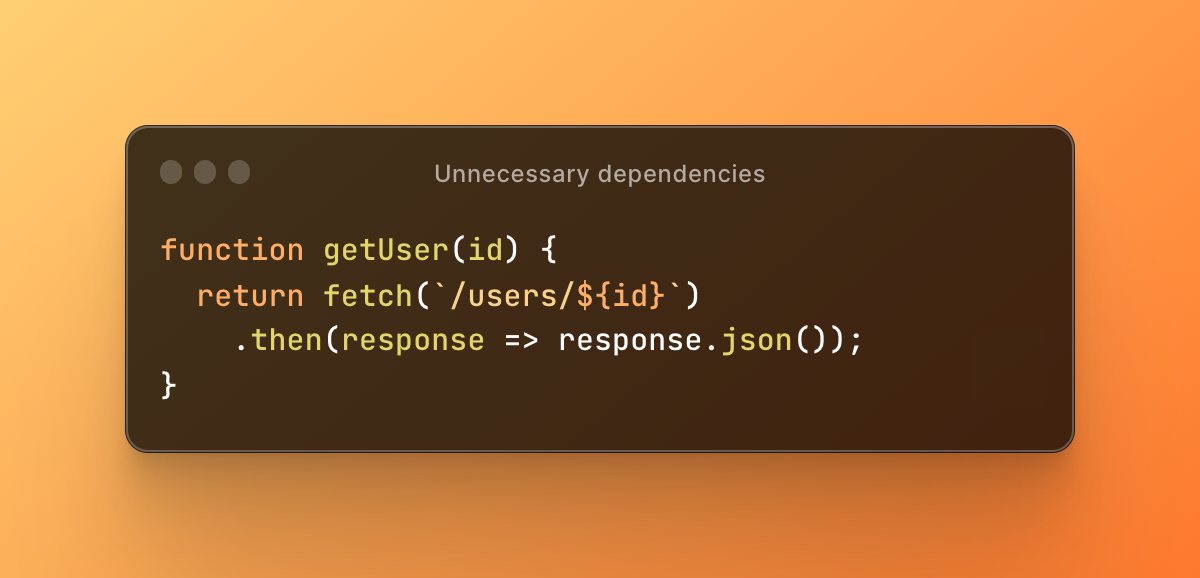
The solution presented removes the unnecessary dependency on Axios and replaces it with the built-in fetch API, making the code simpler and more efficient. Here's the modified code:
Using magic numbers or hard-coded values in code can make it more difficult to understand and maintain. Magic numbers are unnamed constants that are often used to represent specific values or conditions, while hard-coded values are literal values that are embedded directly into the code. Using constants or configuration files can make code more maintainable and easier to modify.
Here is an example of magic numbers or hard-coded values:

In this example, the original code uses the value of 100 as a discount threshold directly in the if statement, which is a magic number.
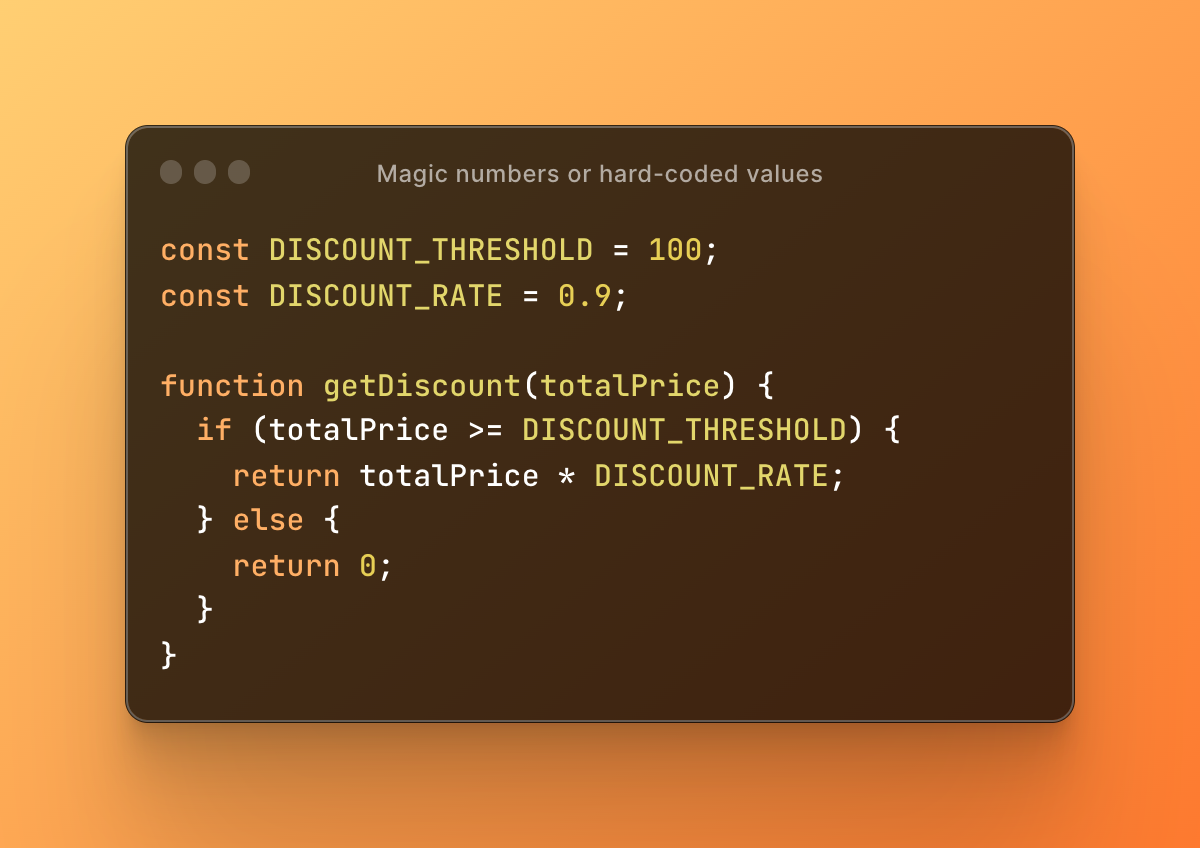
The solution is to define this value as a constant with a meaningful name, and the same is done for the discount rate. This makes the code more readable, easier to understand, and allows for easier changes to the values in the future if needed.
The Importance of Addressing Code Smells in Software Development
Overall, this article highlights the importance of identifying and addressing code smells in pull requests, as they can often indicate underlying problems in a codebase. By taking the time to refactor confusing code and adopt best practices, developers can improve the maintainability, reliability, and overall quality of their code.
However, it's worth noting that not all code smells are created equal. Some may be more benign, while others can have more severe consequences. For example, excessive comments may simply make code harder to read, while incomplete error handling can lead to unpredictable behavior and user frustration.
So, while it's important to address code smells when they arise, it's also important to prioritize them based on their potential impact. And, as with any aspect of software development, it's always better to be proactive than reactive. By implementing good coding practices from the start and regularly reviewing code for potential issues, developers can avoid many of the common code smells that can plague a codebase.